





Internships
We are always on the lookout for summer PhD research interns to work on text to image generation, interactive and multi-turn editing and Multimodal models. If you are interested, reach out to me via email or linkedin with your CV. Below is a list of current and past summer interns.
2024
Maitreya Jitendra Patel (ASU) - Disentangled Representation Learning
Song Wen (Rutgers) - Object Centric Representation Learning
Manuel Brack (TU Darmstadt) - Text to Image Generation
Xianghao Kong (UC Riverside) - Image Generation as Scene Composition
2023
Wonwoong Cho (Purdue) - Controllability of Diffusion Models (ECCV 2024)
2024
Maitreya Jitendra Patel (ASU) - Disentangled Representation Learning
Song Wen (Rutgers) - Object Centric Representation Learning
Manuel Brack (TU Darmstadt) - Text to Image Generation
Xianghao Kong (UC Riverside) - Image Generation as Scene Composition
2023
Wonwoong Cho (Purdue) - Controllability of Diffusion Models (ECCV 2024)
Research Projects / Industry
Highlighting projects and softwares that I developed or led the development of.
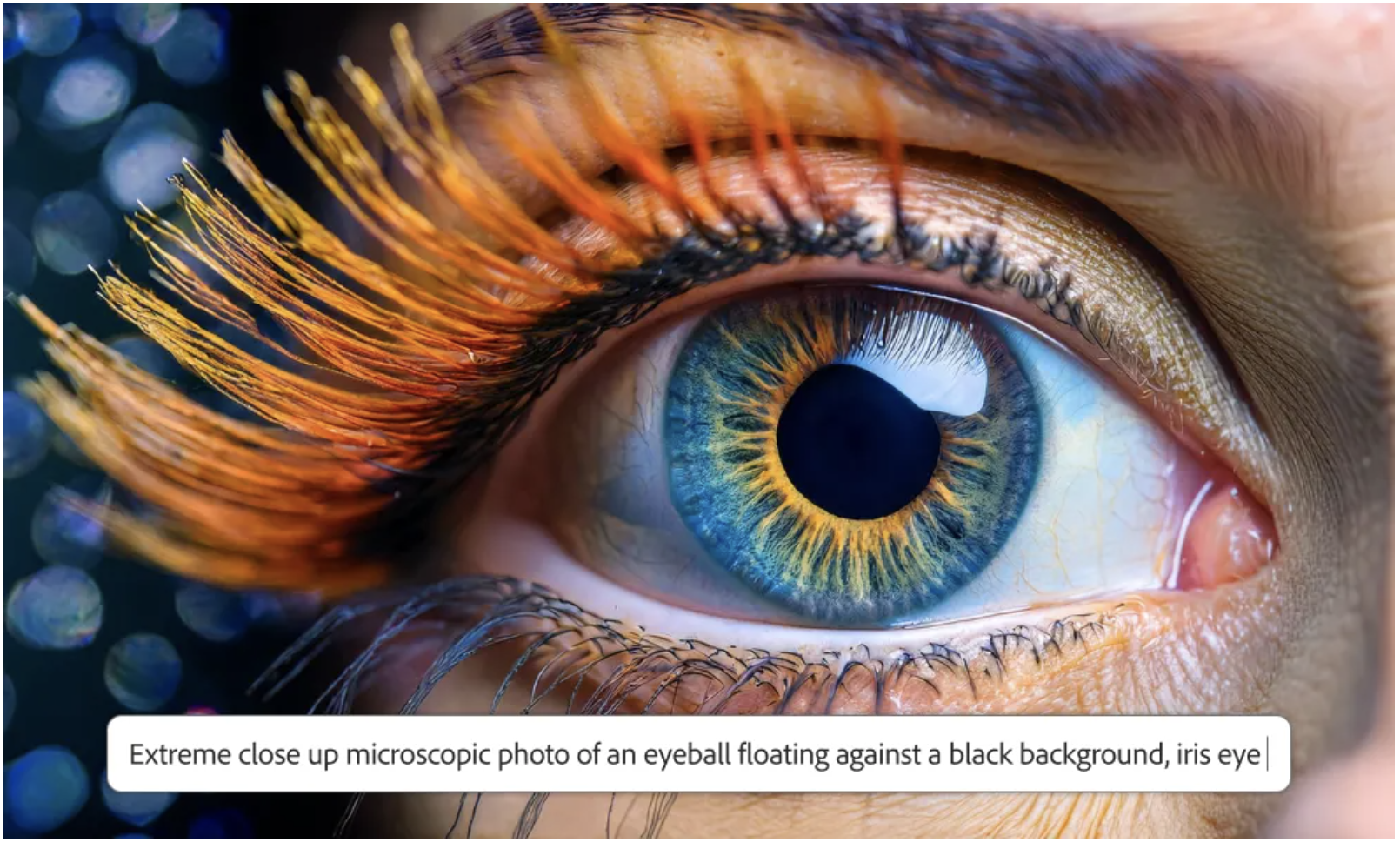
Adobe's latest text to image generative model, FireFly Image Model 3 with higher quality and text to image alignment. News coverage in tech radar, PC Mag, Venture Beat and The Verge. I was the technical lead of this project and contributed to the core architecture, training and inference improvements.
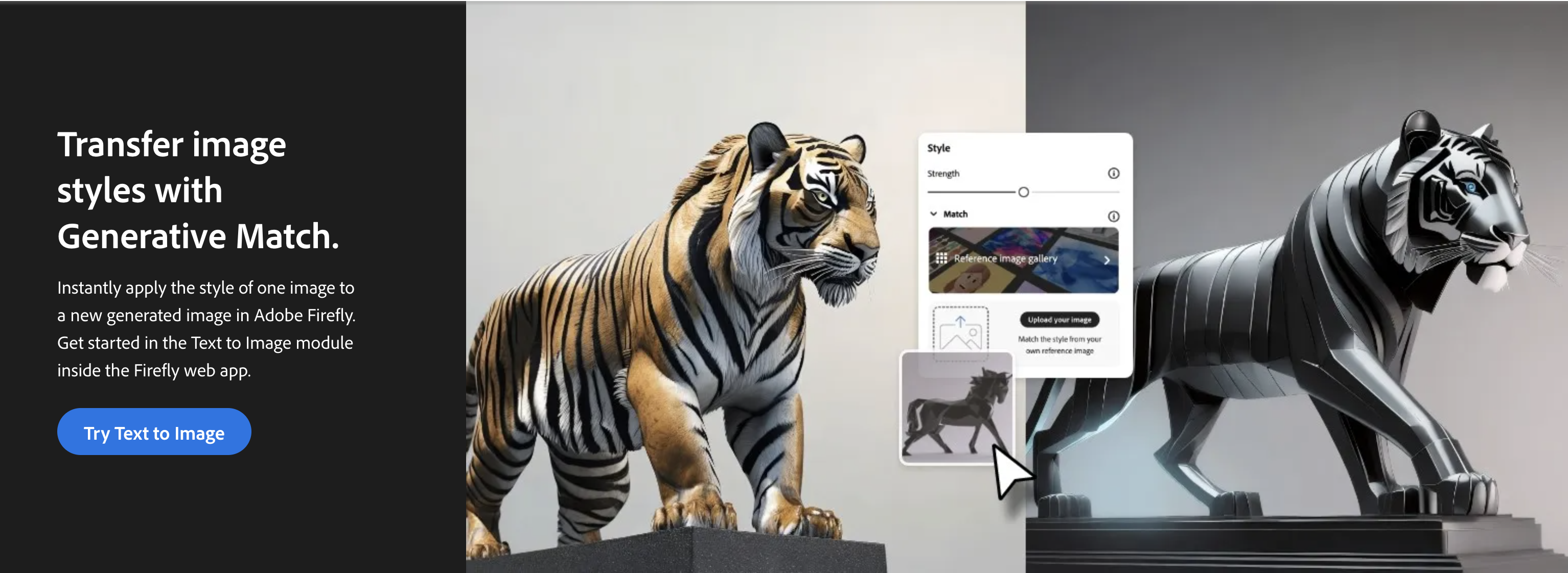
State of the art zero shot stylized image generation enables generating an image conditioned on text prompt and a style reference image released in FireFly Image Model 2. Selected news articles that talk about the model and its capabilities are CG Channel, Tech crunch, AI Business. The feature is based on my patent on zero-shot stylized image generation on Diffusion models.
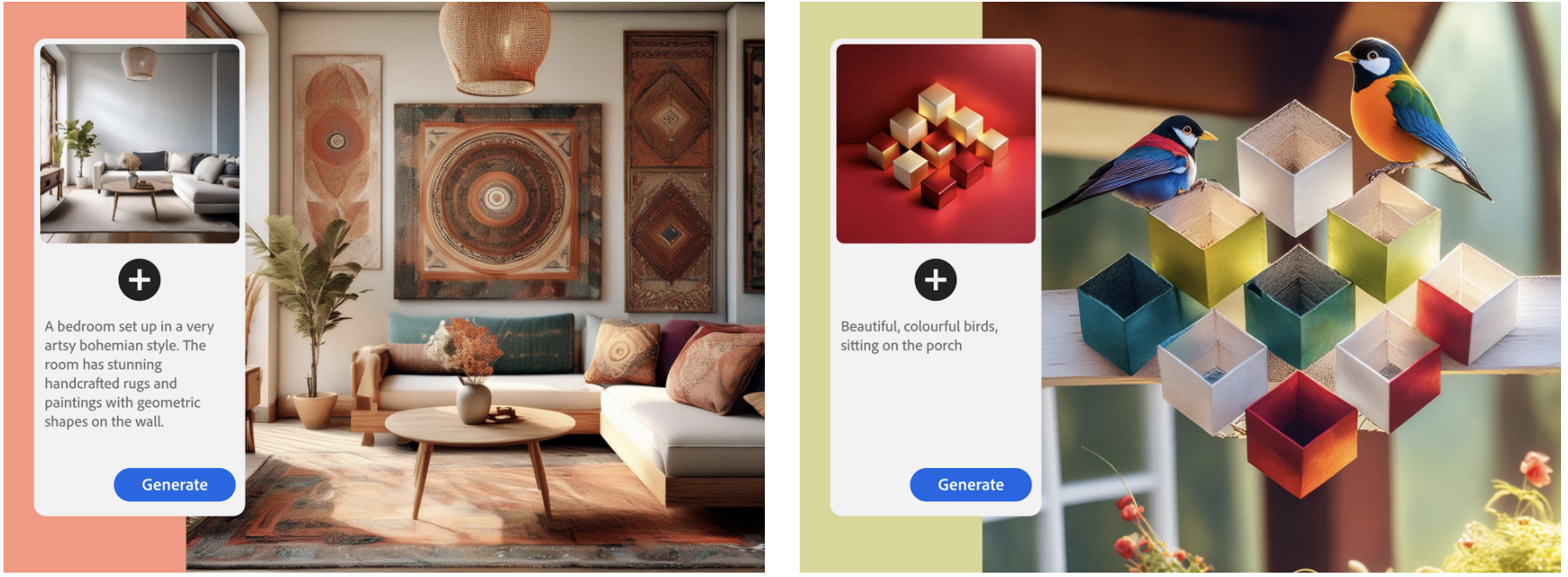
Structure Match enables generating an image conditioned on a text prompt and a reference image to match the structure released in FireFly Image Model 2. Structure and Style match both were rated as best in class by ZDNet. I was the technical lead of this project.
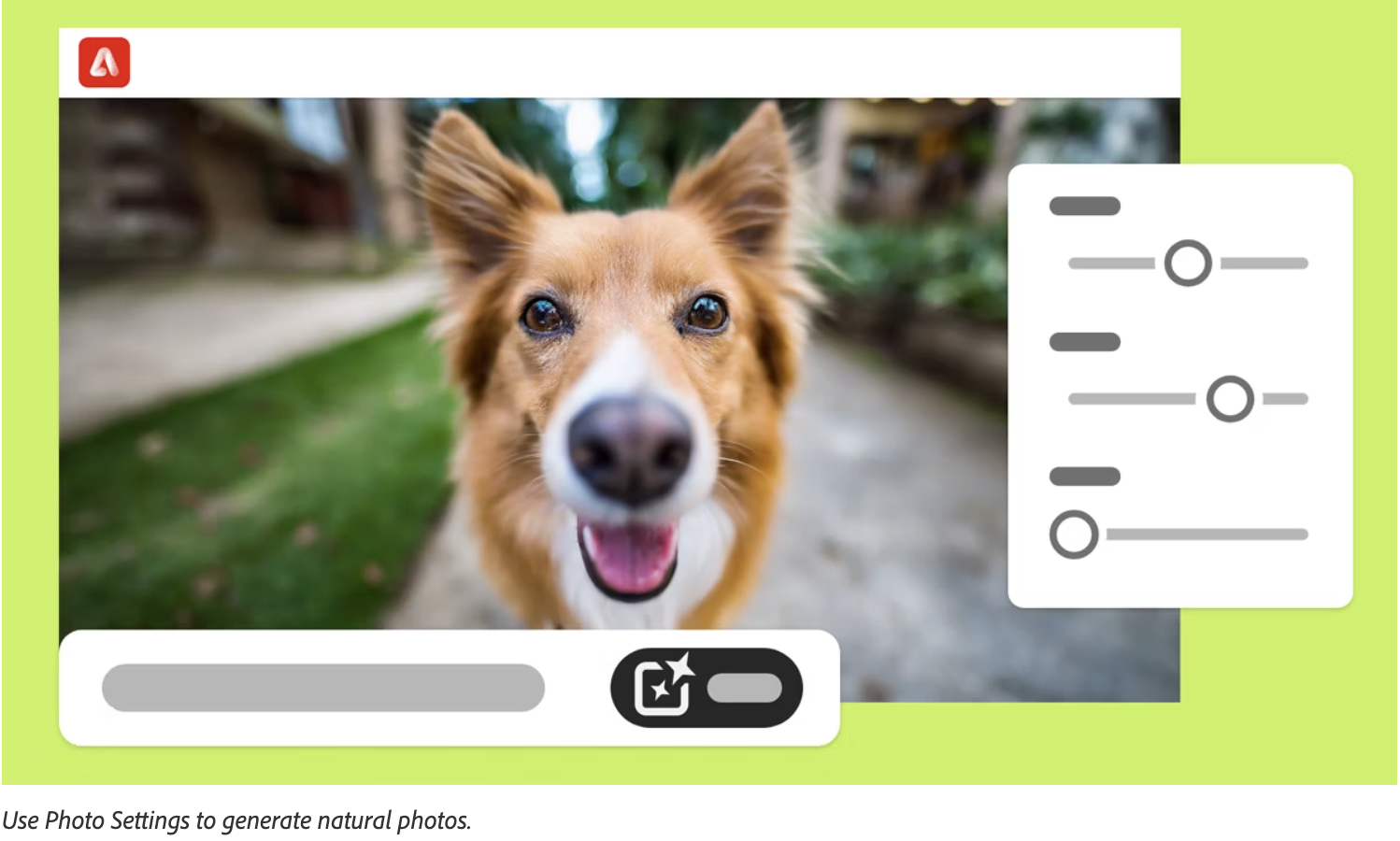
Photographic and content type control on Adobe's FireFly Image Model 2 based on our research. Here is the release blog from Adobe. Project was part of the FireFly 2 project that I co-led.
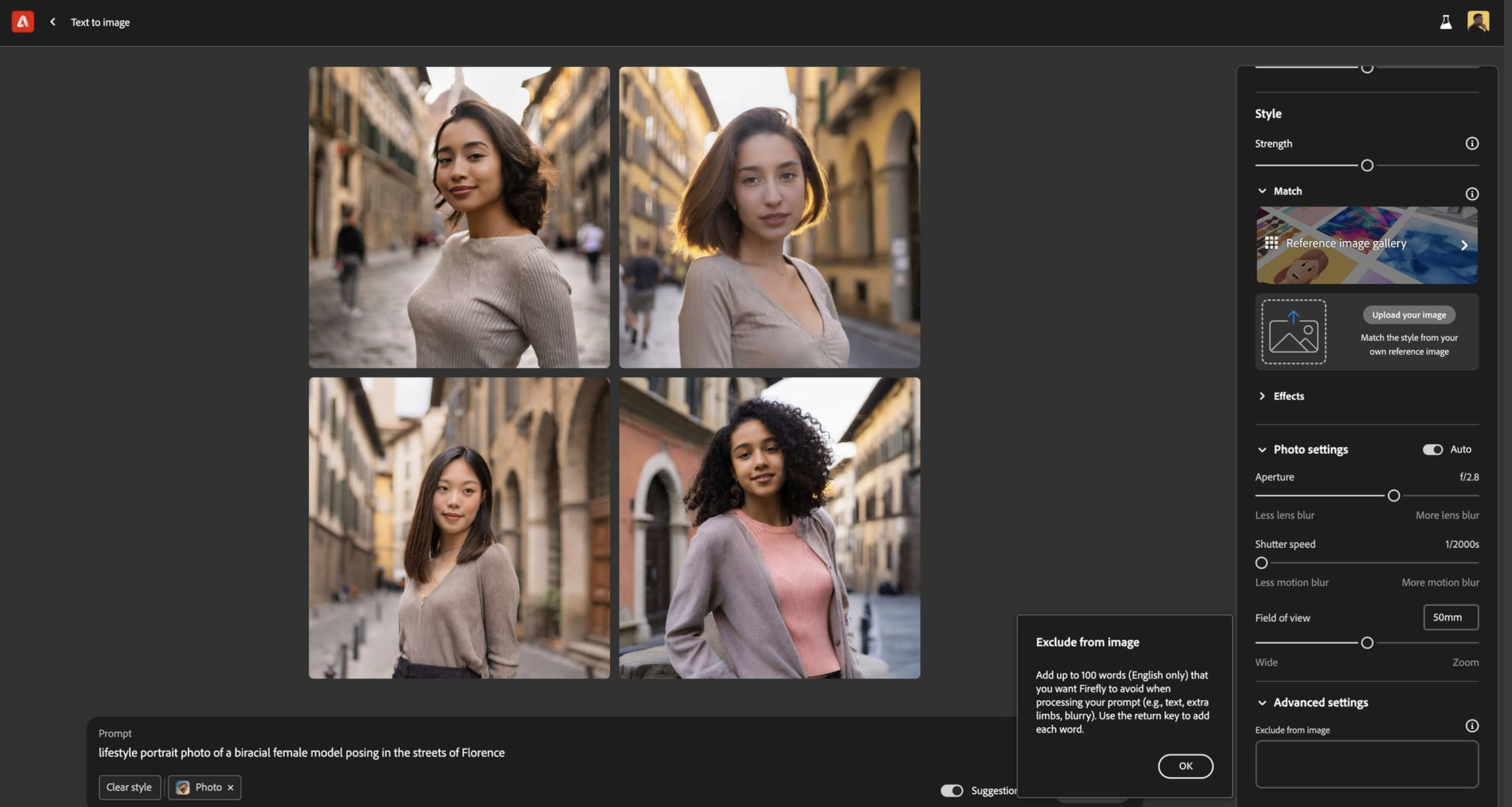
FireFly Image Model 2, Adobe's text to image generative model that gives high quality, aesthetics and reaslism and trained only on copyrighted data. Selectd news articales that covered the model include CNET, Tech crunch, AI Business. I contributed to the core architectural design choices that improved realism, text to image alignment and aesthetics and was the co technical lead of the project.
Selected Research Publications

Enhanced Controllability of Diffusion Models via Feature Disentanglement and Realism-Enhanced Sampling Methods
Wonwoong Cho, Hareesh Ravi, Midhun Harikumar, Vinh Khuc, Krishna Kumar Singh, Jingwan Lu, David I. Inouye, Ajinkya Kale
ECCV 2024
Wonwoong Cho, Hareesh Ravi, Midhun Harikumar, Vinh Khuc, Krishna Kumar Singh, Jingwan Lu, David I. Inouye, Ajinkya Kale
ECCV 2024

PREDITOR: Text Guided Image Editing with Diffusion Prior
Hareesh Ravi, Sachin Kelkar, Midhun Harikumar, Ajinkya Kale
Preprint 2023
Hareesh Ravi, Sachin Kelkar, Midhun Harikumar, Ajinkya Kale
Preprint 2023

Controlled and Conditional Text to Image Generation with Diffusion Prior
Pranav Aggarwal, Hareesh Ravi, ..., Ajinkya Kale
Preprint 2023
Pranav Aggarwal, Hareesh Ravi, ..., Ajinkya Kale
Preprint 2023
Cross-Modal Coherence Model for Text to Image Retrieval
Hareesh Ravi, Malihe Alikhani, Fangda Han, Mubbasir Kapadia Vladimir Pavlovic Mathew Stone
AAAI 2022
Hareesh Ravi, Malihe Alikhani, Fangda Han, Mubbasir Kapadia Vladimir Pavlovic Mathew Stone
AAAI 2022

AESOP: Abstract Encoding of Storied Objects and Pictures
Hareesh Ravi, Kushal Kafle, Scott Cohen, Jonathan Brandt Mubbasir Kapadia
ICCV 2021
Hareesh Ravi, Kushal Kafle, Scott Cohen, Jonathan Brandt Mubbasir Kapadia
ICCV 2021
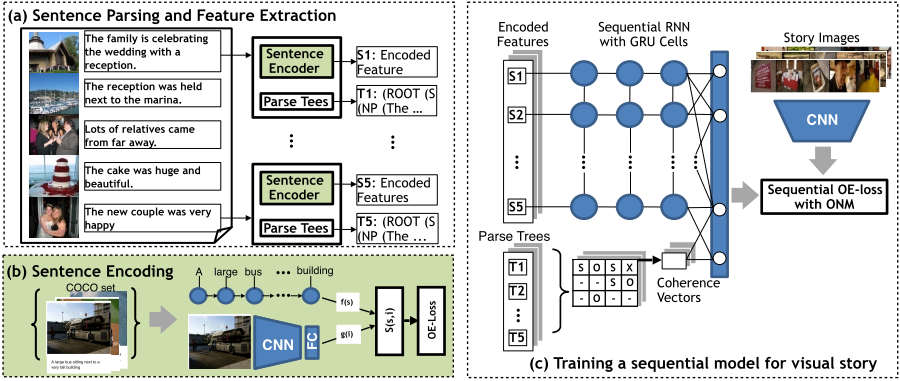
Show Me a Story: Towards Coherent Neural Story Illustration
Hareesh Ravi, Lezi Wang, Carlos Muniz, Leonid Sigal Dimitris Metaxas Mubbasir Kapadia
CVPR 2017
Hareesh Ravi, Lezi Wang, Carlos Muniz, Leonid Sigal Dimitris Metaxas Mubbasir Kapadia
CVPR 2017
Work Experience

May, 2020 - Aug, 2020
Deep Learning Research Intern
Advisers: Dr. Scott Cohen, Dr. Kushal Kafle, Dr. Jonathan Brandt
Deep Learning Research Intern
Advisers: Dr. Scott Cohen, Dr. Kushal Kafle, Dr. Jonathan Brandt


Teaching Experience
Teaching Assistant (Fall 2016)
Intro to Discrete Structures
Teaching Assistant (Spring 2017)
Principles of Programming Languages
Teaching Assistant (Fall 2017)
Topics in AI - Data StoryTelling
Teaching Assistant (Spring 2021)
Intro to Discrete Structures
Professional Experience
Program Committee
CVPR 2024
Program Committee
AAAI 2023, CVPR 2023
Program Committee
AAAI 2022, CVPR 2022, WACV 2022, ECCV 2022
Program Committee
NAACL 2021, ACL 2021
Reviewer
EMNLP 2020