
Research Projects
PREDITOR

We explore text guided image editing with a Hybrid Diffusion Model (HDM) architecture similar to DALLE-2. Our architecture consists of a diffusion prior model that generates CLIP image embedding conditioned on a text prompt and a custom Latent Diffusion Model trained to generate images conditioned on CLIP image embedding. We discover that the diffusion prior model can be used to perform text guided conceptual edits on the CLIP image embedding space without any finetuning or optimization. We combine this with structure preserving edits on the image decoder using existing approaches such as reverse DDIM to perform text guided image editing. Our approach, PRedItOR does not require additional inputs, fine-tuning, optimization or objectives and shows on par or better results than baselines qualitatively and quantitatively.
Enhancing Controllability of Diffusion Models

Inspired by techniques based on the latent space of GAN models for image manipulation, we propose to train a diffusion model conditioned on two latent codes, a spatial content mask and a flattened style embedding. We rely on the inductive bias of the progressive denoising process of diffusion models to encode pose/layout information in the spatial structure mask and semantic/style information in the style code. We extend the sampling technique from composable diffusion models to allow for some dependence between conditional inputs. This improves the quality of the generations significantly while also providing control over the amount of guidance from each latent code separately as well as from their joint distribution.
AESOP

We introduce AESOP: a new dataset that captures the creative process associated with visual storytelling. Visual panels are composed of clip-art objects with specific attributes
enabling a broad range of creative expression. Using AESOP, we propose foundational storytelling tasks that are generative variants
of story cloze tests, to better measure the creative and causal reasoning ability required for visual storytelling. We further develop a
generalized story completion framework that models stories as the co-evolution of visual and textual concepts. We benchmark the proposed
approach with human baselines and evaluate using comprehensive qualitative and quantitative metrics.
Visualize Your Story

UNDER REVIEW: Story illustration is the task of illustrating a natural language story with a coherent sequence of images.
We propose a more generalized task: Many-to-Many Story Illustration, i.e. automatic visualization of a textual story by a coherent sequence of
images of any length. We introduce a novel many-to-many dataset created by aligning natural language descriptions with corresponding
coherent sequence of images sampled from video clips. An end-to-end encoder-decoder neural architecture is proposed that sequentially
retrieves a coherent sequence of images given an input story. User studies show the applicability of the proposed task and dataset
and reveal that the illustrations generated by the proposed model are comparable to the ground truth.
GitEvolve
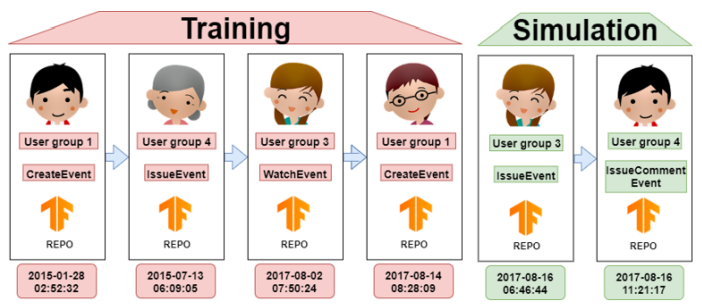
GitEvolve is a multi-task sequential deep network for simulation of future github events given past events for a particular repository. Each event is
characterized by a 3-tuple including type of the event, user cluster id and the time stamp of the event. The three tasks are
trained simultaneously. Social structure of Github is further modelled by automatically learning graph based representation for each
repository. The effectiveness of the proposed technique is evaluated using an array of metrics.
Show Me a Story
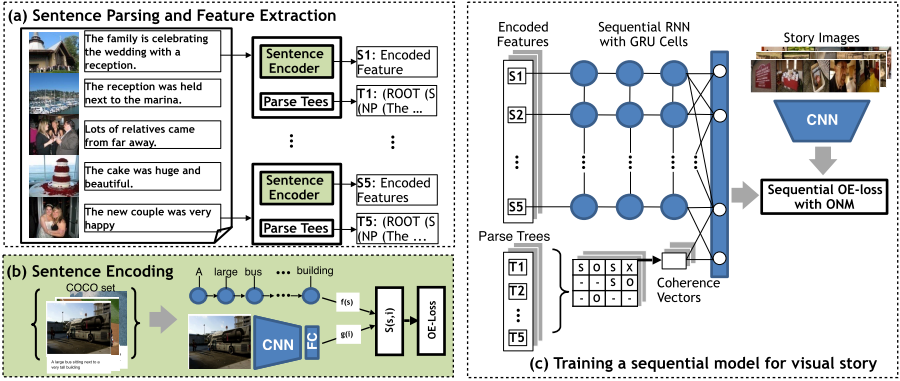
Story Illustration is the problem of retrieving/generating a sequence of images,
given a natural language story as input. We propose a hierarchical GRU network that learns
a representation for the input story and use it to retrieve an ordered set of images from a dataset.
In its core, the model is designed to explicitly model coherence between sentences in a story
optimized over sequential order embedding based loss function. The performance is qualitatively and quantitatively evaluated.
Anti-Forensic Enhancement
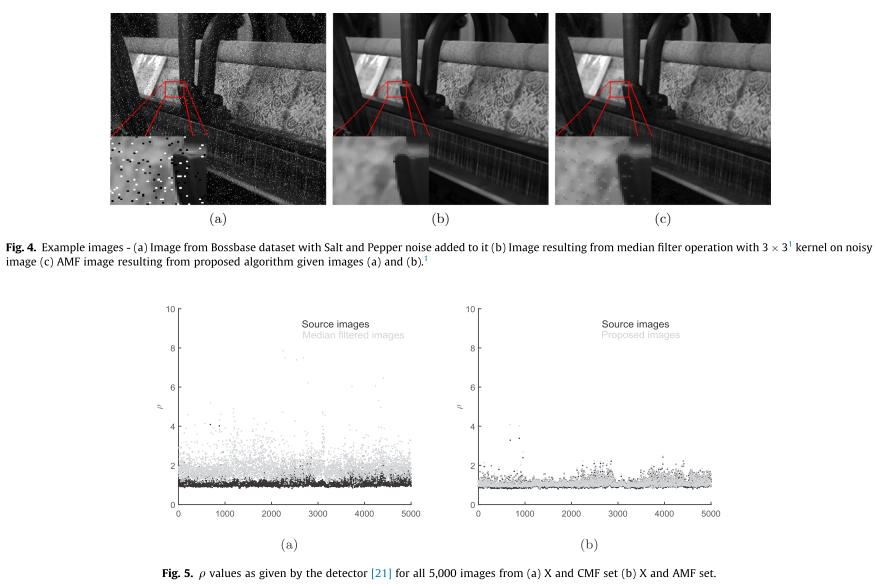
Digital images can be convincingly edited using image editing tools. In order to identify such image pro-cessing operations,
various forensic techniques have been proposed. In response, anti-forensic operationsdesigned as counter-measures have been
devised. We propose an anti-forensic technique tocounter spatial domain forensic detectors and demonstrate its accuracy on
popular image manipulation operations such as median filtering and contrast enhancement. Through a series of experiments,
we prove that the proposed algorithm canseverely degrade the performance of median filtering and contrast enhancement detectors.
The proposedalgorithm also outperforms popular anti-forensic algorithms.
Image Filtering Detection
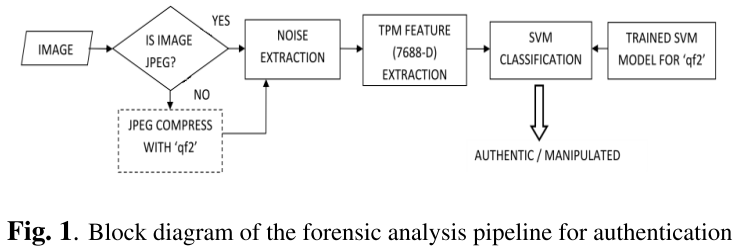
Smart image editing and processing techniques make it easier to manipulate an image convincingly and also hide any artifacts of
tampering using operations like filtering, compression and/or format conversion to suppress forgery artifacts. We propose an
algorithm to detect if a given image has undergone filtering based enhancement irrespective of the format of image or the type
of filter applied using spatial domain quantization noise.